
Dune, Survivor Bias and the National Student Survey
At the time of writing Dune Part Two has just been released in cinemas. The film is of course based on the 1965 book Dune, which has many fascinating themes. One of these is around what makes the Sardaukar - the troops of the Padishah Emperor the second most élite soldiers of the known universe, […]

Budgeting for Assessment
Workloads for Academics in Higher Education are often very complex, with teaching loads, research tasks and administration all juggling for our attention with lots of task switching adding to the complexity. For many academics, teaching loads are a significant part of their work, but explicitly looking at the time spent on assessment could bring better […]

The Tyranny of Resilience and the New Normal
In the midst of the COVID-19 pandemic there is a word and a short phrase that are both in very common usage. All too often they are used in unhelpful and arguably incorrect ways. Elasticity has Limits Resilience has an interesting etymology, coming from the Latin ‘resilire’, ‘to recoil or rebound’. It came to encompass […]

Battleships Server / Client for Education
I've been teaching a first year introductory module in Python programming for Engineering at Ulster University for a few years now. As part of the later labs I have let the students build a battleships game using Object Oriented Programming - with "Fleet" objects containing a list of "Ships" and so on where they could […]

Assessment handling and Assessment Workflow in WAM
Sometime ago I began writing a Workload Allocation Modeller aimed at Higher Education, and I've written some previous blog articles about this. As is often the way, the scope of the project broadened and I found myself writing in support for handling assessments and the QA processes around them. At some point this necessitates a […]

Semi Open Book Exams
A few years ago, I switched one of my first year courses to use what I call a semi-open-book approach. Open-book exams of course allow students to bring whatever materials they wish into them, but they have the disadvantage that students will often bring in materials that they have not studied in detail, or even […]
Pretty Printing C++ Archives from Emails
I'm just putting this here because I nearly managed to lose it. This is a part of a pretty unvarnished BASH script for a very specific purpose, taking an email file containing a ZIP of submitted C++ code from students. This script produces pretty printed PDFs of the source files named after each author to […]
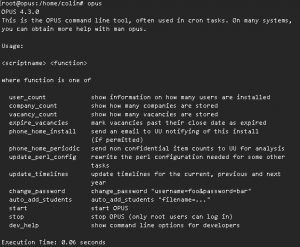
OPUS and Assessment 3 - Regime Change
This is the third and final article in a short series on how OPUS, a system for managing placement on-line, handles assessment. You probably want to read the first and second article before getting into this. Regime Change It's not just in geo-political diplomacy that regime change is a risky proposition. In general you should […]
OPUS and Assessment 2 - Adding Custom Assessments
This is a follow on to the previous article on setting up assessment in OPUS, an on-line system for placement learning. You probably want to read that first. This is much more advanced and requires some technical knowledge (or someone that has that). Making New Assessments Suppose that OPUS doesn't have the assessment you want, […]

OPUS and Assessment 1 - The Basics
OPUS is a FOSS (Free and Open Source Software) web application I wrote at Ulster University to manage work based learning. It has been, and is used by some other universities too. Among its features is a way to understand the assessment structure for different groups and how it can change over years in such […]