
Extracting Sky Router Crash Data Amidst Kernel Panics
I have a Sky broadband connection with fibre into a Sky Router / Sky Hub. I have noticed very short outages of internet service with increasing frequency recently. The outages are short, maybe around 3-5 minutes long but these are annoying enough in the middle of an online meeting or some other synchronous activity. Sometimes […]

Battleships Server / Client for Education
I've been teaching a first year introductory module in Python programming for Engineering at Ulster University for a few years now. As part of the later labs I have let the students build a battleships game using Object Oriented Programming - with "Fleet" objects containing a list of "Ships" and so on where they could […]

Anatomy of a Puzzle
Recently I was asked to provide a Puzzle For Today for the BBC Radio 4 Today programme which was partially coming as an Outside Broadcast from Ulster University. I've written a post about the puzzle itself, and some of the ramifications of it; this post is really more about the thought process that went into […]
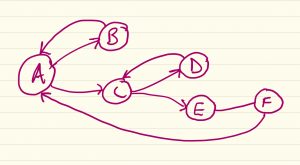
Implementing configurable work-flow patterns in Python Django
In my previous article, I discussed some of changes I've made to my WAM software to handle assessment and work-flow. I thought I'd have a look at this from the technical side for those interested in doing something similar, this is obviously extensible to general workflow management, where you might want to tweak the workflow […]

Assessment handling and Assessment Workflow in WAM
Sometime ago I began writing a Workload Allocation Modeller aimed at Higher Education, and I've written some previous blog articles about this. As is often the way, the scope of the project broadened and I found myself writing in support for handling assessments and the QA processes around them. At some point this necessitates a […]
Migrating Django Migrations to Django 2.x
Django is a Python framework for making web applications, and its impressive in its completeness, flexibility and power for speedy prototyping. It's also an impressive project for forward planning, it has a kind of built in "lint" functionality that warns about deprecated code that will be disallowed in future versions. As a result when Django […]

Semi Open Book Exams
A few years ago, I switched one of my first year courses to use what I call a semi-open-book approach. Open-book exams of course allow students to bring whatever materials they wish into them, but they have the disadvantage that students will often bring in materials that they have not studied in detail, or even […]
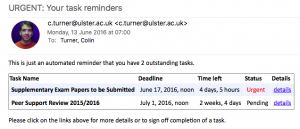
Workload Allocation Modelling Update - Scalability
I have been doing some more work on my software to handle Academic Workload Modelling, developing a roadmap for two future versions, one being modifications needed to run real allocations for next year without scrapping existing data, and another being code to handle the moderation of exams and coursework (which isn't really anything to do […]
Manually completing a botched django migration
I wrote a lot of code for my Workload Allocation system on Friday, and had been developing it on the machine with django's built in lightweight web server, and a (default) sqlite database backend. In production I decided to use a MySQL backend in case sqlite was, well, too lite. One of the things that […]
Workload Allocation Monitoring (WAM) Prototype
I decided to start writing a workload allocation monitoring system for Higher Education. I found one written as part of a JISC project at Cambridge, but despite my experience with PHP I found it difficult to set-up, a bit crude (sorry) and hard to maintain. It was clearly very flexible, and I wanted something flexible, […]