
20 years since shodan - reflections on gradings, mastery and imposter syndrome
Today (5th August 2021) marks twenty years since I first graded to shodan (the first black belt grade) in a martial art. It might come as a surprise to many non martial artists that there are multiple black belt grades, and that a black belt does not represent the end of a journey but more […]

Beef in Soy Sauce
This is a version of a recipe my Mum had that I have experimented with in for a slow cooker format. I've pared this down to the most simple version I can. I usually run this recipe by eye, but one of my daughters wants to have a go at it, so I decided I'd […]

Budgeting for Assessment
Workloads for Academics in Higher Education are often very complex, with teaching loads, research tasks and administration all juggling for our attention with lots of task switching adding to the complexity. For many academics, teaching loads are a significant part of their work, but explicitly looking at the time spent on assessment could bring better […]

The Tyranny of Resilience and the New Normal
In the midst of the COVID-19 pandemic there is a word and a short phrase that are both in very common usage. All too often they are used in unhelpful and arguably incorrect ways. Elasticity has Limits Resilience has an interesting etymology, coming from the Latin ‘resilire’, ‘to recoil or rebound’. It came to encompass […]

Bread without commercial yeast - Sour-dough
At the time of writing, an extraordinary number of people are in some sort of lockdown, and trying to go the shops less often, and when they do, certain items are in short supply. One of those items is commercial yeast. If you still have access to flour (preferably strong flour), salt and water, you […]

Battleships Server / Client for Education
I've been teaching a first year introductory module in Python programming for Engineering at Ulster University for a few years now. As part of the later labs I have let the students build a battleships game using Object Oriented Programming - with "Fleet" objects containing a list of "Ships" and so on where they could […]

Anatomy of a Puzzle
Recently I was asked to provide a Puzzle For Today for the BBC Radio 4 Today programme which was partially coming as an Outside Broadcast from Ulster University. I've written a post about the puzzle itself, and some of the ramifications of it; this post is really more about the thought process that went into […]
My Puzzle for the Day
In November 2018 the BBC Radio 4 Today Programme was visiting Ulster University for an outside broadcast. I was asked to write the Puzzle for the Day for the broadcast. Here is my puzzle and some discussion about how it can be solved. The puzzle and a very brief solution is on the BBC page, […]

Review: The Very Short Introduction
Infinity, A Very Short Introduction, by Ian Stewart This review was originally written for the London Mathematical Society November 2018 Newsletter. The book can be found here. The “Very Short Introduction” series by Oxford University Press attempt to take a moderately deep dive into various subjects in a slimline volume. Professor Stuart addresses the apparent […]
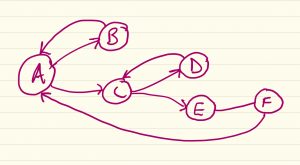
Implementing configurable work-flow patterns in Python Django
In my previous article, I discussed some of changes I've made to my WAM software to handle assessment and work-flow. I thought I'd have a look at this from the technical side for those interested in doing something similar, this is obviously extensible to general workflow management, where you might want to tweak the workflow […]